Table of Contents
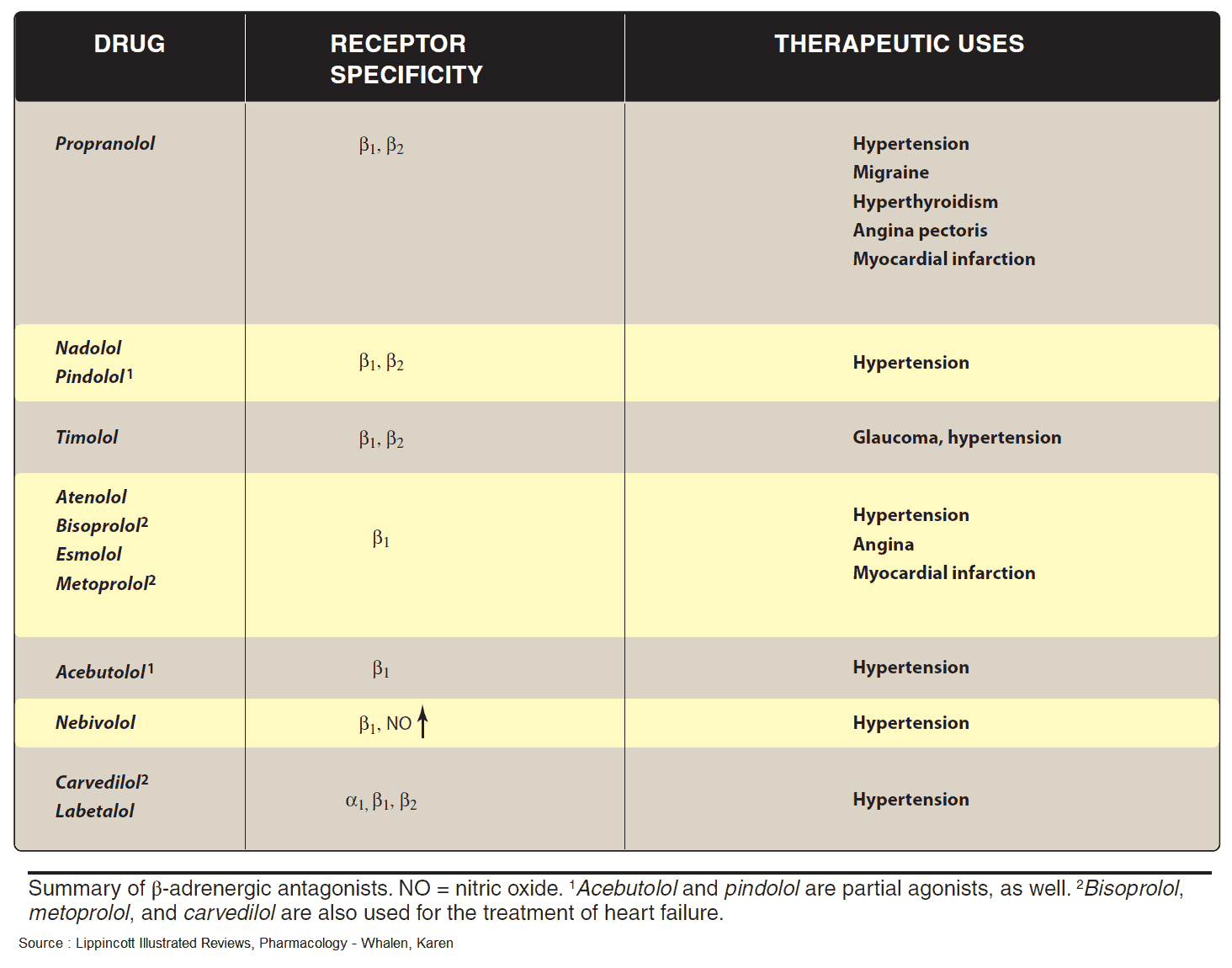
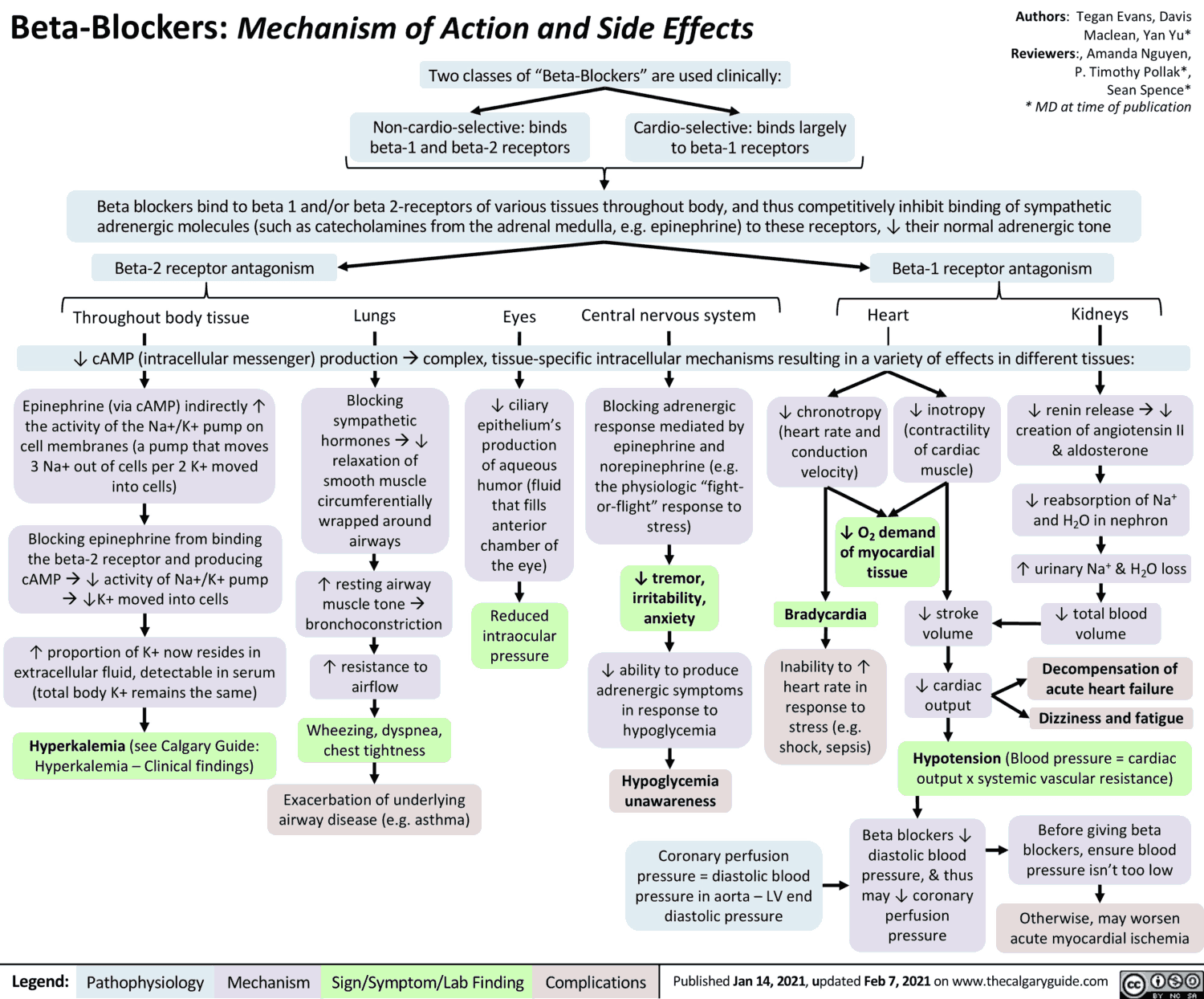
Beta-Sympatholytics (Beta Blockers) are antagonists of norepiphephrine and epinephrine at β- adrenoceptors; they lack affinity for alpha-receptors.
Indications and Therapeutic Effects of Beta-Sympatholytics (Beta Blockers)
- Hypertension (by reducing cardiac output and renin secretion)
- Supraventricular Tachycardias (by slowing AV conduction velocity)
- Angina Pectoris (by reducing cardiac rate and force)
- Migraine (for prophylaxis)
- Thyrotoxicosis
- Arrhythmia prophylaxis after myocardial infarction
- Glaucoma (by reducing secretion of aqueous humor)

Beta-Blockers protect the heart from the oxygen wasting effect of sympathetic inotropism by blocking cardiac beta-receptors; thus, cardiac work can no longer be augmented above basal levels (the heart is “coasting”). This effect is utilized prophylactically in angina pectoris to prevent myocardial stress that could trigger an ischemic attack.
Beta-Blockers also serve to lower cardiac rate (sinus tachycardia, supraventricular tachycardia) and lower elevated blood pressure due to high cardiac output. The mechanism underlying their antihypertensive action via reduction of peripheral resistance is unclear.
Applied topically to the eye, Beta blockers are used in the management of glaucoma; they lower production of aqueous humor without affecting its drainage.
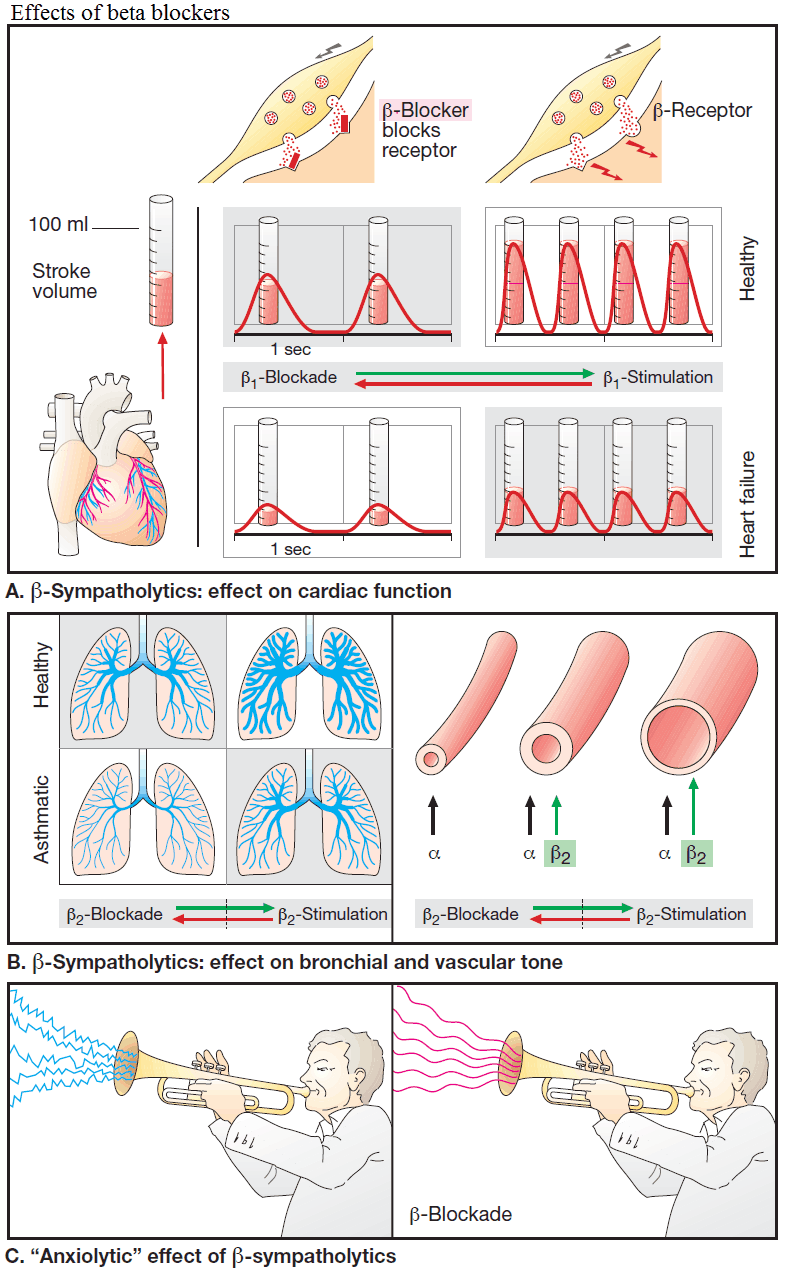
β-Blockers exert an “anxiolytic“ action that may be due to the suppression of somatic responses (palpitations, trembling) to epinephrine release that is induced by emotional stress; in turn, these would exacerbate “anxiety” or “stage fright”. Because alertness is not impaired by β-blockers, these agents are occasionally taken by orators and musicians before a major performance. Stage fright, however, is not a disease requiring drug therapy.
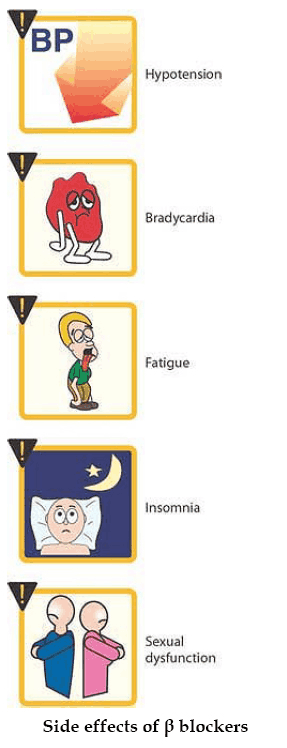
Side Effects of Beta-Sympatholytics (Beta Blockers)
The hazards of treatment with Beta-blockers become apparent particularly when continuous activation of Beta-receptors is needed in order to maintain the function of an organ.
Congestive heart failure
In myocardial insufficiency, the heart depends on a tonic sympathetic drive to maintain adequate cardiac output. Sympathetic activation gives rise to an increase in heart rate and systolic muscle tension, enabling cardiac output to be restored to a level comparable to that in a healthy subject.
When sympathetic drive is eliminated during beta-receptor blockade, stroke volume and cardiac rate decline, a latent myocardial insufficiency is unmasked, and overt insufficiency is exacerbated. On the other hand, clinical evidence suggests that beta-blockers produce favorable effects in certain forms of congestive heart failure (idiopathic dilated cardiomyopathy).
Bradycardia, A-V block
Elimination of sympathetic drive can lead to a marked fall in cardiac rate as well as to disorders of impulse conduction from the atria to the ventricles.
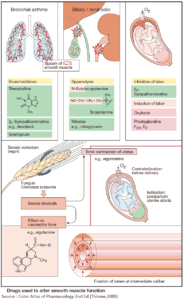
Bronchial asthma
Increased sympathetic activity prevents bronchospasm in patients disposed to paroxysmal constriction of the bronchial tree (bronchial asthma, bronchitis in smokers). In this condition, β2-receptor blockade will precipitate acute respiratory distress.
Hypoglycemia in diabetes mellitus
When treatment with insulin or oral hypoglycemics in the diabetic patient lowers blood glucose below a critical level, epinephrine is released, which then stimulates hepatic glucose release via activation of β2-receptors.
Beta-Blockers suppress this counter-regulation; in addition, they mask other epinephrine mediated warning signs of imminent hypoglycemia, such as tachycardia and anxiety, thereby enhancing the risk of hypoglycemic shock.
Altered vascular responses
When β2-receptors are blocked, the vasodilating effect of epinephrine is abolished, leaving the α-receptor-mediated vasoconstriction unaffected: peripheral blood flow ↓ – “cold hands and feet”.
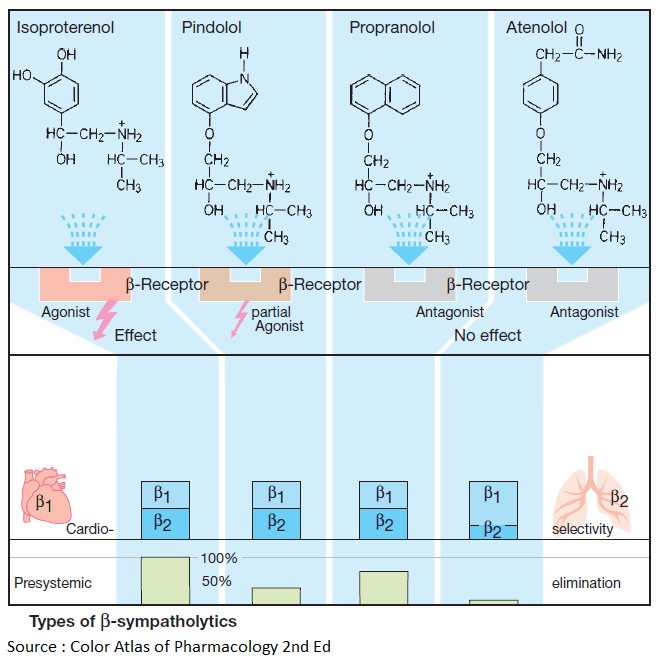
Types of Beta Blockers
The basic structure shared by most Beta – sympatholytics is the side chain of Beta-sympathomimetics (cf. isoproterenol with the β-blockers propranolol, pindolol, atenolol). As a rule, this basic structure is linked to an aromatic nucleus by a methylene and oxygen bridge. The side chain C-atom bearing the hydroxyl group forms the chiral center.
With some exceptions (e.g., timolol, penbutolol), all Beta-sympatholytics are brought as racemates into the market. Compared with the dextrorotatory form, the levorotatory enantiomer possesses a greater than 100-fold higher affinity for the β-receptor and is, therefore, practically alone in contributing to the β-blocking effect of the racemate.
The side chain and substituents on the amino group critically affect affinity for β-receptors, whereas the aromatic nucleus determines whether the compound possess intrinsic sympathomimetic activity (ISA), that is, acts as a partial agonist or partial antagonist.
In the presence of a partial agonist (e.g., pindolol), the ability of a full agonist (e.g., isoprenaline) to elicit a maximal effect would be attenuated, because binding of the full agonist is impeded. However, the β-receptor at which such partial agonism can be shown appears to be atypical (β3 or β4 subtype). Whether ISA confers a therapeutic advantage on a Beta-blocker remains an open question.
As cationic amphiphilic drugs, Beta-blockers can exert a membrane-stabilizing effect, as evidenced by the ability of the more lipophilic congeners to inhibit Na+-channel function and impulse conduction in cardiac tissues. At the usual therapeutic dosage, the high concentration required for these effects will not be reached.
Some Beta-sympatholytics possess higher affinity for cardiac β1-receptors than for β2-receptors and thus display cardioselectivity (e.g., metoprolol, acebutolol, bisoprolol). None of these blockers is sufficiently selective to permit its use in patients with bronchial asthma or diabetes mellitus.
The chemical structure of Beta-blockers also determines their pharmacokinetic properties. Except for hydrophilic representatives (atenolol), Beta-sympatholytics are completely absorbed from the intestines and subsequently undergo presystemic elimination to a major extent.
All the above differences are of little clinical importance. The abundance of commercially available congeners would thus appear all the more curious. Propranolol was the first Beta-blocker to be introduced into therapy in 1965. Thirty-five years later, about 20 different congeners are being marketed in different countries.
This questionable development unfortunately is typical of any drug group that has major therapeutic relevance, in addition to a relatively fixed active structure.
Variation of the molecule will create a new patentable chemical, not necessarily a drug with a novel action. Moreover, a drug no longer protected by patent is offered as a generic by different manufacturers under dozens of different proprietary names. Propranolol alone has been marketed by 13 manufacturers under 11 different names.